Note
Go to the end to download the full example code
Missing Data Periods#
Identifying days with missing data using a “completeness” score metric.
Identifying days with missing data and filtering these days out reduces noise
when performing data analysis. This example shows how to use a
daily data “completeness” score to identify and filter out days with missing
data. This includes using
pvanalytics.quality.gaps.completeness_score(),
pvanalytics.quality.gaps.complete(), and
pvanalytics.quality.gaps.trim_incomplete().
import pvanalytics
from pvanalytics.quality import gaps
import matplotlib.pyplot as plt
import pandas as pd
import pathlib
First, we import the AC power data stream that we are going to check for completeness. The time series we download is a normalized AC power time series from the PV Fleets Initiative, and is available via the DuraMAT DataHub: https://datahub.duramat.org/dataset/inverter-clipping-ml-training-set-real-data. This data set has a Pandas DateTime index, with the min-max normalized AC power time series represented in the ‘value_normalized’ column. The data is sampled at 15-minute intervals. This data set does contain NaN values.
pvanalytics_dir = pathlib.Path(pvanalytics.__file__).parent
file = pvanalytics_dir / 'data' / 'ac_power_inv_2173.csv'
data = pd.read_csv(file, index_col=0, parse_dates=True)
data = data.asfreq("15min")
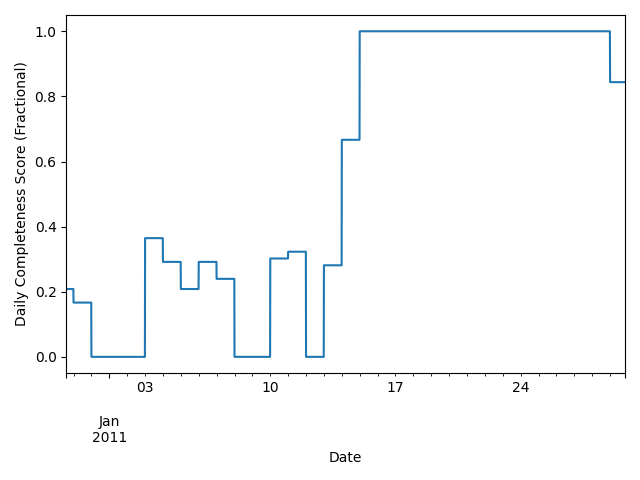
Now, we use pvanalytics.quality.gaps.completeness_score() to get the
percentage of daily data that isn’t NaN. This percentage score is calculated
as the total number of non-NA values over a 24-hour period, meaning that
nighttime values are expected.
data_completeness_score = gaps.completeness_score(data['value_normalized'])
# Visualize data completeness score as a time series.
data_completeness_score.plot()
plt.xlabel("Date")
plt.ylabel("Daily Completeness Score (Fractional)")
plt.tight_layout()
plt.show()
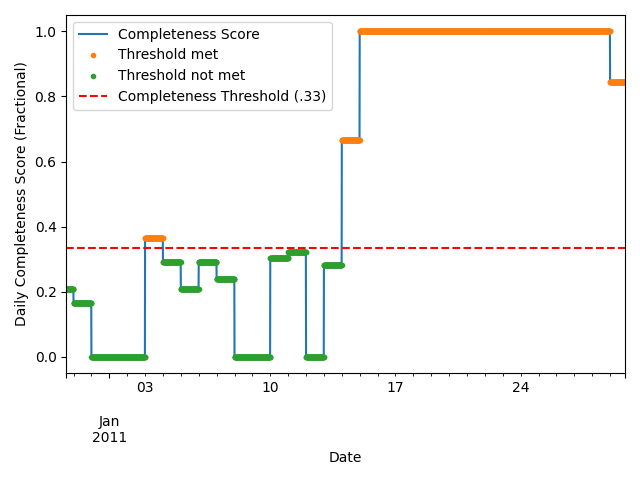
We mask complete days, based on daily completeness score, using
pvanalytics.quality.gaps.complete().
min_completeness = 0.333
daily_completeness_mask = gaps.complete(data['value_normalized'],
minimum_completeness=min_completeness)
# Mask complete days, based on daily completeness score
data_completeness_score.plot()
data_completeness_score.loc[daily_completeness_mask].plot(ls='', marker='.')
data_completeness_score.loc[~daily_completeness_mask].plot(ls='', marker='.')
plt.axhline(y=min_completeness, color='r', linestyle='--')
plt.legend(labels=["Completeness Score", "Threshold met",
"Threshold not met", "Completeness Threshold (.33)"],
loc="upper left")
plt.xlabel("Date")
plt.ylabel("Daily Completeness Score (Fractional)")
plt.tight_layout()
plt.show()
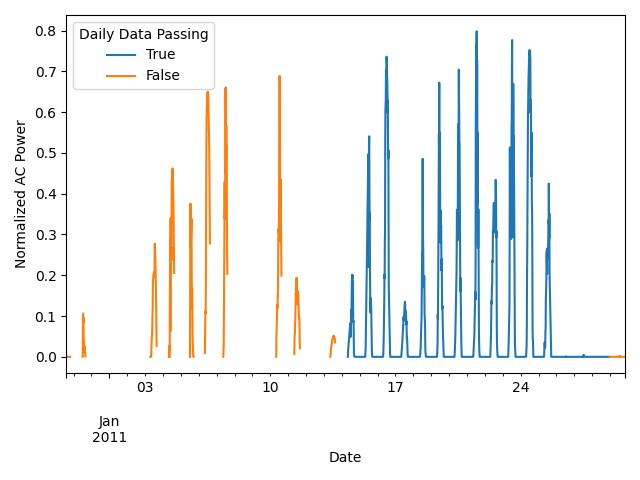
We trim the time series based on the completeness score, where the time
series must have at least 10 consecutive days of data that meet the
completeness threshold. This is done using
pvanalytics.quality.gaps.trim_incomplete().
number_consecutive_days = 10
completeness_trim_mask = gaps.trim_incomplete(data['value_normalized'],
days=number_consecutive_days)
# Re-visualize the time series with the data masked by the trim mask
data[completeness_trim_mask]['value_normalized'].plot()
data[~completeness_trim_mask]['value_normalized'].plot()
plt.legend(labels=[True, False],
title="Daily Data Passing")
plt.xlabel("Date")
plt.ylabel("Normalized AC Power")
plt.tight_layout()
plt.show()
Total running time of the script: (0 minutes 1.017 seconds)