Note
Go to the end to download the full example code
PV Fleets QA Process: Temperature#
PV Fleets Temperature QA Pipeline
The NREL PV Fleets Data Initiative uses PVAnalytics routines to assess the quality of systems’ PV data. In this example, the PV Fleets process for assessing the data quality of a temperature data stream is shown. This example pipeline illustrates how several PVAnalytics functions can be used in sequence to assess the quality of a temperature data stream.
import pandas as pd
import pathlib
from matplotlib import pyplot as plt
import pvanalytics
from pvanalytics.quality import data_shifts as ds
from pvanalytics.quality import gaps
from pvanalytics.quality.outliers import zscore
First, we import a module temperature data stream from a PV installation at NREL. This data set is publicly available via the PVDAQ database in the DOE Open Energy Data Initiative (OEDI) (https://data.openei.org/submissions/4568), under system ID 4. This data is timezone-localized.
pvanalytics_dir = pathlib.Path(pvanalytics.__file__).parent
file = pvanalytics_dir / 'data' / 'system_4_module_temperature.parquet'
time_series = pd.read_parquet(file)
time_series.set_index('index', inplace=True)
time_series.index = pd.to_datetime(time_series.index)
time_series = time_series['module_temp_1']
latitude = 39.7406
longitude = -105.1774
# Identify the temperature data stream type (this affects the type of
# checks we do)
data_stream_type = "module"
data_freq = '15min'
time_series = time_series.asfreq(data_freq)
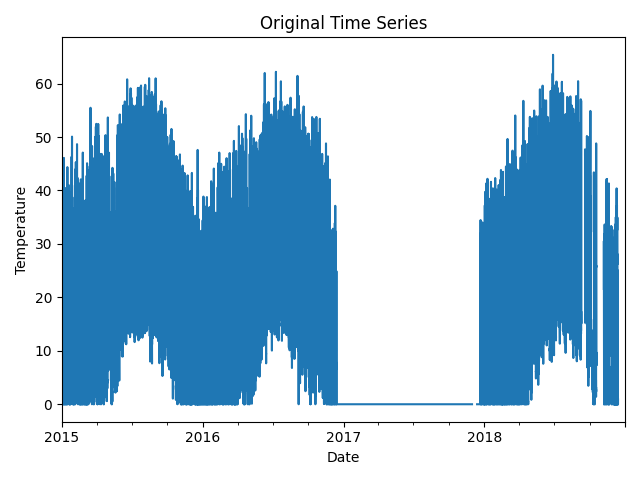
First, let’s visualize the original time series as reference.
time_series.plot(title="Original Time Series")
plt.xlabel("Date")
plt.ylabel("Temperature")
plt.tight_layout()
plt.show()
Now, let’s run basic data checks to identify stale and abnormal/outlier data in the time series. Basic data checks include the following steps:
Flatlined/stale data periods (
pvanalytics.quality.gaps.stale_values_round())“Abnormal” data periods, which are out of the temperature limits of -40 to 185 deg C. Additional checks based on thresholds are applied depending on the type of temperature sensor (ambient or module) (
pvanalytics.quality.weather.temperature_limits())Outliers, which are defined as more than one 4 standard deviations away from the mean (
pvanalytics.quality.outliers.zscore())
Additionally, we identify the units of the temperature stream as either Celsius or Fahrenheit.
# REMOVE STALE DATA
stale_data_mask = gaps.stale_values_round(time_series,
window=3,
decimals=2)
# FIND ABNORMAL PERIODS
temperature_limit_mask = pvanalytics.quality.weather.temperature_limits(
time_series, limits=(-40, 185))
temperature_limit_mask = temperature_limit_mask.reindex(
index=time_series.index,
method='ffill',
fill_value=False)
# FIND OUTLIERS (Z-SCORE FILTER)
zscore_outlier_mask = zscore(time_series,
zmax=4,
nan_policy='omit')
# PERFORM ADDITIONAL CHECKS, INCLUDING CHECKING UNITS (CELSIUS OR FAHRENHEIT)
temperature_mean = time_series.mean()
if temperature_mean > 35:
temp_units = 'F'
else:
temp_units = 'C'
print("Estimated Temperature units: " + str(temp_units))
# Run additional checks based on temperature sensor type.
if data_stream_type == 'module':
if temp_units == 'C':
module_limit_mask = (time_series <= 85)
temperature_limit_mask = (temperature_limit_mask & module_limit_mask)
if data_stream_type == 'ambient':
ambient_limit_mask = pvanalytics.quality.weather.temperature_limits(
time_series, limits=(-40, 120))
temperature_limit_mask = (temperature_limit_mask & ambient_limit_mask)
if temp_units == 'C':
ambient_limit_mask_2 = (time_series <= 50)
temperature_limit_mask = (temperature_limit_mask &
ambient_limit_mask_2)
# Get the percentage of data flagged for each issue, so it can later be logged
pct_stale = round((len(time_series[
stale_data_mask].dropna())/len(time_series.dropna())*100), 1)
pct_erroneous = round((len(time_series[
~temperature_limit_mask].dropna())/len(time_series.dropna())*100), 1)
pct_outlier = round((len(time_series[
zscore_outlier_mask].dropna())/len(time_series.dropna())*100), 1)
# Visualize all of the time series issues (stale, abnormal, outlier)
time_series.plot()
labels = ["Temperature"]
if any(stale_data_mask):
time_series.loc[stale_data_mask].plot(ls='',
marker='o',
color="green")
labels.append("Stale")
if any(~temperature_limit_mask):
time_series.loc[~temperature_limit_mask].plot(ls='',
marker='o',
color="yellow")
labels.append("Abnormal")
if any(zscore_outlier_mask):
time_series.loc[zscore_outlier_mask].plot(ls='',
marker='o',
color="purple")
labels.append("Outlier")
plt.legend(labels=labels)
plt.title("Time Series Labeled for Basic Issues")
plt.xlabel("Date")
plt.ylabel("Temperature")
plt.tight_layout()
plt.show()
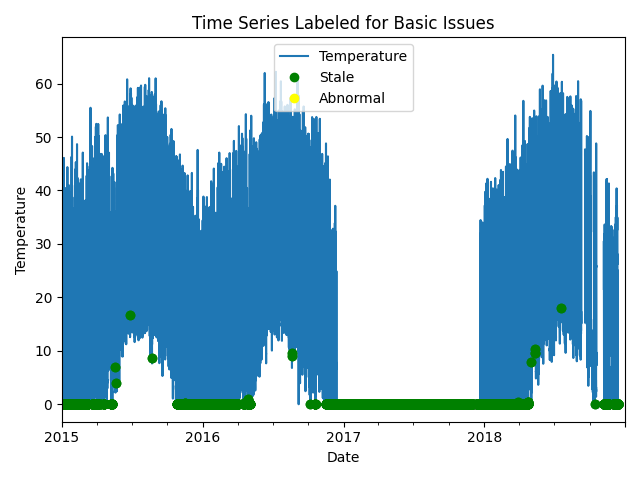
Estimated Temperature units: C
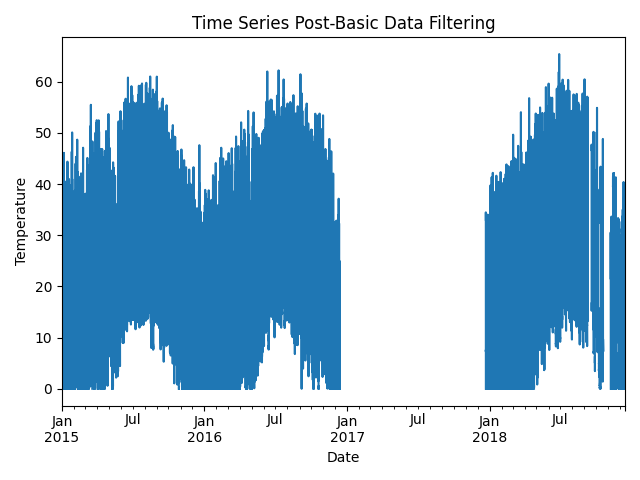
Now, let’s filter out any of the flagged data from the basic temperature checks (stale or abnormal data). Then we can re-visualize the data post-filtering.
# Filter the time series, taking out all of the issues
issue_mask = ((~stale_data_mask) & (temperature_limit_mask) &
(~zscore_outlier_mask))
time_series = time_series[issue_mask]
time_series = time_series.asfreq(data_freq)
# Visualize the time series post-filtering
time_series.plot(title="Time Series Post-Basic Data Filtering")
plt.xlabel("Date")
plt.ylabel("Temperature")
plt.tight_layout()
plt.show()
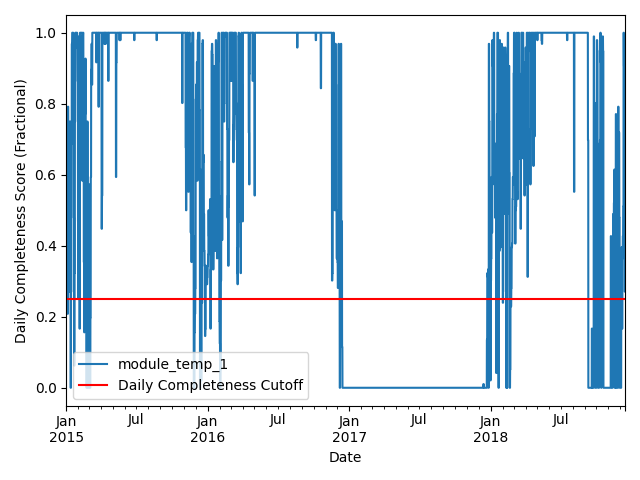
We filter the time series based on its daily completeness score. This filtering scheme requires at least 25% of data to be present for each day to be included. We further require at least 10 consecutive days meeting this 25% threshold to be included.
# Visualize daily data completeness
data_completeness_score = gaps.completeness_score(time_series)
# Visualize data completeness score as a time series.
data_completeness_score.plot()
plt.xlabel("Date")
plt.ylabel("Daily Completeness Score (Fractional)")
plt.axhline(y=0.25, color='r', linestyle='-',
label='Daily Completeness Cutoff')
plt.legend()
plt.tight_layout()
plt.show()
# Trim the series based on daily completeness score
trim_series = pvanalytics.quality.gaps.trim_incomplete(
time_series,
minimum_completeness=.25,
freq=data_freq)
first_valid_date, last_valid_date = \
pvanalytics.quality.gaps.start_stop_dates(trim_series)
time_series = time_series[first_valid_date.tz_convert(time_series.index.tz):
last_valid_date.tz_convert(time_series.index.tz)]
time_series = time_series.asfreq(data_freq)
Next, we check the time series for any abrupt data shifts. We take the
longest continuous part of the time series that is free of data shifts.
We use pvanalytics.quality.data_shifts.detect_data_shifts() to
detect data shifts in the time series.
# Resample the time series to daily mean
time_series_daily = time_series.resample('D').mean()
data_shift_start_date, data_shift_end_date = \
ds.get_longest_shift_segment_dates(time_series_daily)
data_shift_period_length = (data_shift_end_date -
data_shift_start_date).days
# Get the number of shift dates
data_shift_mask = ds.detect_data_shifts(time_series_daily)
# Get the shift dates
shift_dates = list(time_series_daily[data_shift_mask].index)
if len(shift_dates) > 0:
shift_found = True
else:
shift_found = False
# Visualize the time shifts for the daily time series
print("Shift Found: ", shift_found)
edges = ([time_series_daily.index[0]] + shift_dates +
[time_series_daily.index[-1]])
fig, ax = plt.subplots()
for (st, ed) in zip(edges[:-1], edges[1:]):
ax.plot(time_series_daily.loc[st:ed])
plt.title("Daily Time Series Labeled for Data Shifts")
plt.xlabel("Date")
plt.ylabel("Mean Daily Temperature")
plt.tight_layout()
plt.show()
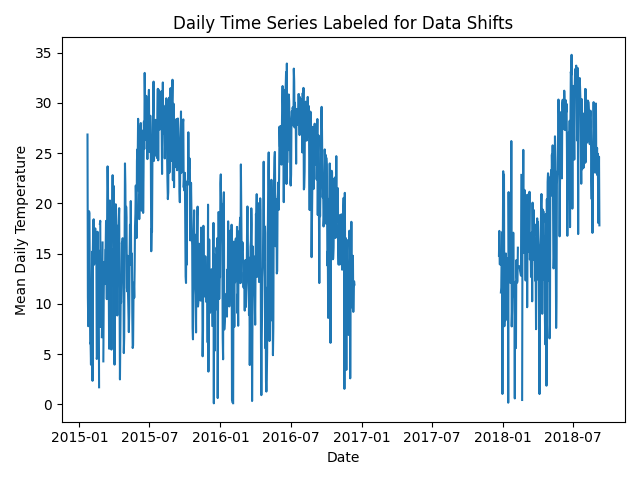
Shift Found: False
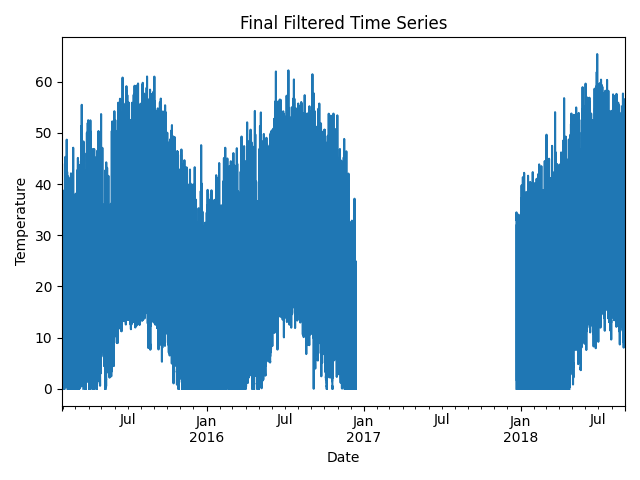
Finally, we filter the time series to only include the longest shift-free period. We then visualize the final time series post-QA filtering.
time_series = time_series[
(time_series.index >=
data_shift_start_date.tz_convert(time_series.index.tz)) &
(time_series.index <=
data_shift_end_date.tz_convert(time_series.index.tz))]
time_series = time_series.asfreq(data_freq)
# Plot the final filtered time series.
time_series.plot(title="Final Filtered Time Series")
plt.xlabel("Date")
plt.ylabel("Temperature")
plt.tight_layout()
plt.show()
Generate a dictionary output for the QA assessment of this data stream, including the percent stale and erroneous data detected, any shift dates, and the detected temperature units for the data stream.
qa_check_dict = {"temperature_units": temp_units,
"pct_stale": pct_stale,
"pct_erroneous": pct_erroneous,
"pct_outlier": pct_outlier,
"data_shifts": shift_found,
"shift_dates": shift_dates}
print("QA Results:")
print(qa_check_dict)
QA Results:
{'temperature_units': 'C', 'pct_stale': 36.6, 'pct_erroneous': 0.0, 'pct_outlier': 0.0, 'data_shifts': False, 'shift_dates': []}
Total running time of the script: (0 minutes 13.096 seconds)