pvanalytics.quality.outliers.hampel#
- pvanalytics.quality.outliers.hampel(data, window=5, max_deviation=3.0, scale=None)#
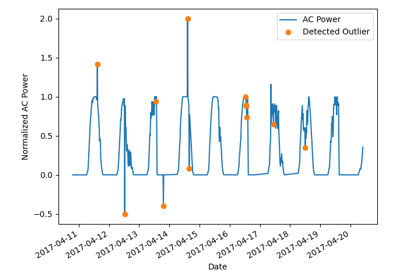
Identify outliers by the Hampel identifier.
The Hampel identifier is computed according to 1.
- Parameters
data (Series) – The data in which to find outliers.
window (int or offset, default 5) – The size of the rolling window used to compute the Hampel identifier.
max_deviation (float, default 3.0) – Any value with a Hampel identifier > max_deviation standard deviations from the median is considered an outlier.
scale (float, optional) – Scale factor used to estimate the standard deviation as \(MAD / scale\). If scale=None (default), then the scale factor is taken to be
scipy.stats.norm.ppf(3/4.)(approx. 0.6745), and \(MAD / scale\) approximates the standard deviation of Gaussian distributed data.
- Returns
True for each value that is an outlier according to its Hampel identifier.
- Return type
Series
References
- 1
Pearson, R.K., Neuvo, Y., Astola, J. et al. Generalized Hampel Filters. EURASIP J. Adv. Signal Process. 2016, 87 (2016). https://doi.org/10.1186/s13634-016-0383-6